关于概率律的函数的期望
考虑一个数值随机现象,其概率函数为 。概率函数 决定了实轴上单位质量的分布,落在任何实数(博雷尔)集 上的质量等于 。为了用几个数字概括 的特征,我们在本节中定义连续函数 关于实变量 ,相对于概率函数 的期望的概念,记作 。将会看到,期望 与 关于一组数的平均值具有许多相同的性质。
对于概率函数 由概率质量函数 指定的情况,我们类比 (1.12) ,定义
(2.1) 中写出的求和可能涉及可数无限多项的求和,因此并非总是有意义的。基于 第8章第1节 中阐明的原因,期望 被称为存在,如果
对于概率函数 由概率密度函数 指定的情况,我们定义
(2.3) 中写出的积分是反常积分,因此并非总是有意义的。在谈论期望 之前,必须验证其存在性。期望 被称为存在,如果
判断由 (2.3) 给出的期望 是否存在的一个有用工具是理论练习 2.1 中给出的反常积分收敛性检验。
关于在概率函数必须由分布函数指定的情况下期望的定义的讨论,见第 6 节。
期望 有时被称为函数 的系综平均值,以强调期望(或系综平均值)是一个理论上计算的量。它并非像第 1 节中的情况那样,是一组观测数字的平均值。我们稍后将考虑相对于随机现象观测值的平均值,这些将被称为样本平均值。
引入了一套专门术语来描述各种函数 的期望 。
我们称 ,即函数 关于一个概率律的期望,为该概率律的均值。对于具有概率质量函数 的离散概率律,
对于具有概率密度函数 的连续概率律,
可以证明,概率律的均值具有以下含义。假设对服从该概率律的随机现象进行一系列独立观测 ,并构造逐次算术平均值
这些逐次算术平均值 将(以概率1)趋于一个极限值,当且仅当该概率律的均值是有限的。此外,这个极限值将恰好是该概率律的均值。
我们称 ,即函数 关于一个概率律的期望,为该概率律的均方。这个概念不应与概率律的平方均值混淆,后者是均值的平方 ,我们将其记作 。对于具有概率质量函数 的离散概率律,
对于具有概率密度函数 的连续概率律,
更一般地,对于任意整数 ,我们称 ,即 关于一个概率律的期望,为该概率律的 n 阶矩。注意,一阶矩和概率律的均值是相同的;同样,二阶矩和概率律的均方是相同的。
接下来,对于任意实数 和整数 ,我们称 为概率律关于点 的 n 阶矩。特别令人感兴趣的是 等于均值 的情况。我们称 为概率律关于其均值的 n 阶矩,或更简洁地,概率律的 n 阶中心矩。
二阶中心矩 尤为重要,被称为概率律的方差。给定一个概率律,我们将使用符号 和 分别表示其均值和方差;因此,
方差的平方根 被称为概率律的标准差。方差的直观含义在第 4 节中讨论。
例 2A 。具有参数 和 的正态概率律由概率密度函数 指定,该函数由第4章的 (4.11) 给出。其均值等于
方程 (2.12) 由第4章的 (2.20) 和 (2.22) 以及以下事实得出:对于任何可积函数
由 (2.12) 和 (2.13) 可知,均值 等于 。接下来,方差等于
取期望的运算具有某些基本性质,利用这些性质可以进行各种形式上的操作。首先,对于任何常数 以及任何期望存在的函数 和 ,我们有以下性质:
方程 (2.15) 到 (2.19) 是期望定义的直接结果。我们仅针对期望是关于具有概率密度函数 的连续概率律来取的情况写出细节。那么,根据积分的性质,
方程 (2.19) 由 (2.18) 得出,首先应用于 和 ,然后应用于 和 。
接下来,我们推导出概率律方差的一个极其重要的表达式:
换言之,概率律的方差等于其均方减去其平方均值。为证明 (2.20) ,我们令 ,写出
在本节的剩余部分,我们计算各种概率律的均值和方差。所得结果的表格在第3节末尾的表 3A 和 3B 中给出。
Example 2C . The Bernoulli probability law with parameter , in which , is specified by the probability mass function , given by for or 1. Its mean, mean square, and variance, letting , are given by
Example 2D . The binomial probability law with parameters and is specified by the probability mass function given by (4.5) of Chapter 4. Its mean is given by
Its mean square is given by
To evaluate , we write . Then
Since , the sum in (2.24) is equal to
Consequently, , so that
Example 2E . The hypergeometric probability law with parameters , and is specified by the probability mass function given by (4.8) of Chapter 4. Its mean is given by
Notice that the mean of the hypergeometric probability law is the same as that of the corresponding binomial probability law, whereas the variances differ by a factor that is approximately equal to 1 if the ratio is a small number.
Example 2F . The uniform probability law over the interval to has probability density function given by (4.10) of Chapter 4. Its mean, mean square, and variance are given by
Note that the variance of the uniform probability law depends only on the length of the interval, whereas the mean is equal to the mid-point of the interval. The higher moments of the uniform probability law are also easily obtained:
Example 2G . The Cauchy probability law with parameters and is specified by the probability density function
The mean of the Cauchy probability law does not exist, since
However, for the th absolute moments
do exist, as one may see by applying theoretical exercise 2.1.
Theoretical Exercises
2.1 . Test for convergence or divergence of infinite series and improper integrals . Prove the following statements. Let be a continuous function. If, for some real number , the limits
both exist and are finite, then
converge absolutely; if, for some , either of the limits in (2.34) exist and is not equal to 0, then the expressions in (2.35) fail to converge absolutely.
2.2 . Pareto’s distribution with parameters and , in which and are positive, is defined by the probability density function
Show that Pareto’s distribution possesses a finite th moment if and only if . Find the mean and variance of Pareto’s distribution in the cases in which they exist.
2.3 . “Student’s” -distribution with parameter is defined as the continuous probability law specified by the probability density function
Note that “Student’s” -distribution with parameter coincides with the Cauchy probability law given by (2.31). Show that for “Student’s” -distribution with parameter (i) the th moment exists only for , (ii) if and is odd, then , (iii) if and is even, then
2.4 . A characterization of the mean . Consider a probability law with finite mean . Define, for every real number . Show that . Consequently is minimized at , and its minimum value is the variance of the probability law.
2.5 . A geometrical interpretation of the mean of a probability law . Show that for a continuous probability law with probability density function and distribution function
Consequently the mean of the probability law may be written
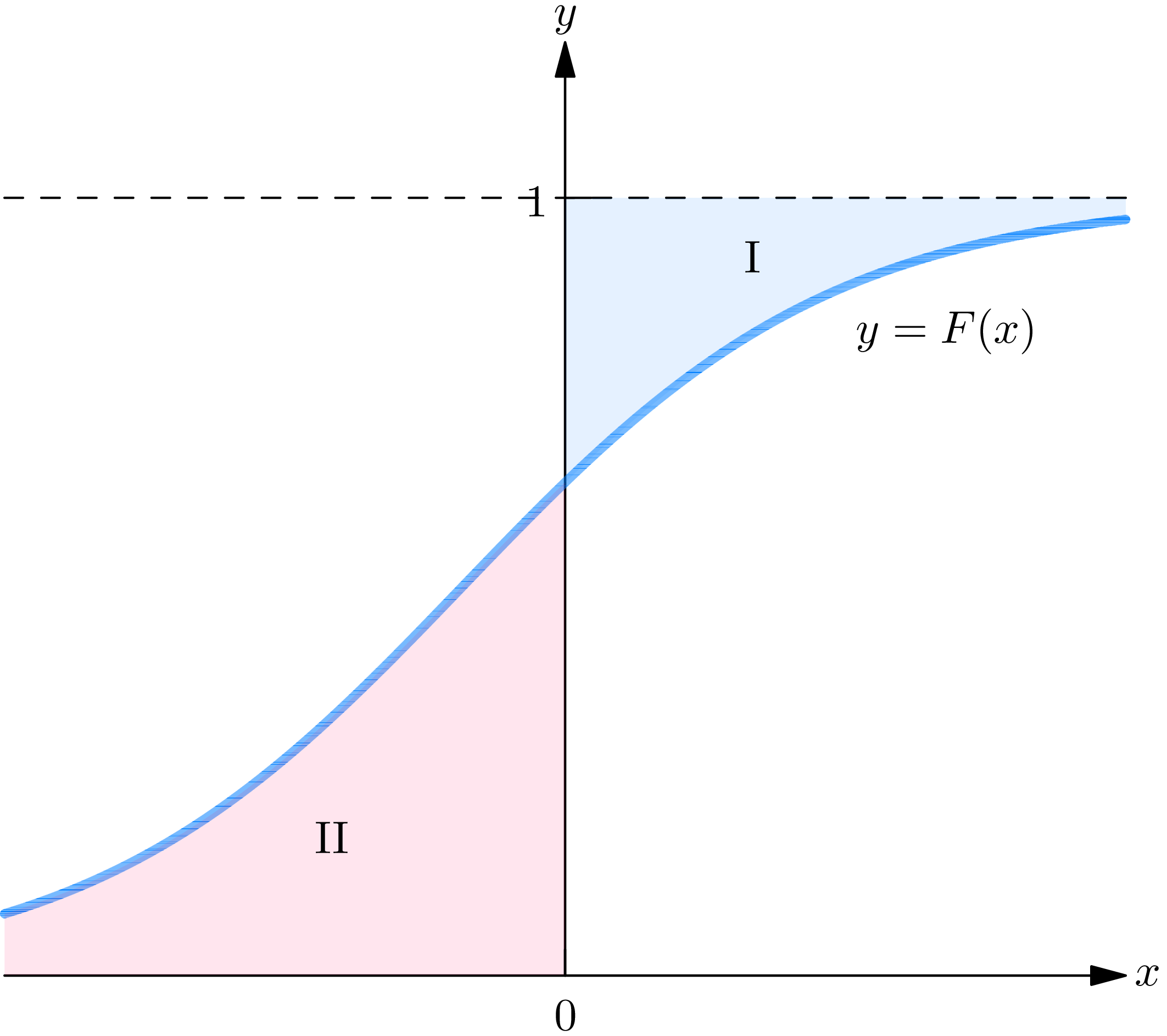
These equations may be interpreted geometrically. Plot the graph of the distribution function on an -plane, as in Fig. 2A, and define the areas I and II as indicated: is the area to the right of the -axis bounded by and ; II is the area to the left of the -axis bounded by and . Then the mean is equal to area I, minus area II. Although we have proved this assertion only for the case of a continuous probability law, it holds for any probability law.
2.6 . A geometrical interpretation of the higher moments . Show that the th moment of a continuous probability law with distribution function can be expressed for
Use (2.41) to interpret the th moment in terms of area.
2.7 . The relation between the moments and central moments of a probability law . Show that from a knowledge of the moments of a probability law one may obtain a knowledge of the central moments, and conversely. In particular, it is useful to have expressions for the first 4 central moments in terms of the moments. Show that
2.8 . The square mean is less than or equal to the mean square . Show that
Give an example of a probability law whose mean square is equal to its square mean.
2.9 . The mean is not necessarily greater than or equal to the variance . The binomial and the Poisson are probability laws having the property that their mean is greater than or equal to their variance (show this); this circumstance has sometimes led to the belief that for the probability law of a random variable assuming only nonnegative values it is always true that . Prove this is not the case by showing that for the probability law of the number of failures up to the first success in a sequence of independent repeated Bernoulli trials.
2.10 . The median of a probability law . The mean of a probability law provides a measure of the “mid-point” of a probability distribution. Another such measure is provided by the median of a probability law , denoted by , which is defined as a number such that
If the probability law is continuous, the median may be defined as a number satisfying . Thus is the projection on the -axis of the point in the -plane at which the line intersects the curve . A more probabilistic definition of the median is as a number such that , in which is an observed value of a random phenomenon obeying the given probability law. There may be an interval of points that satisfies (2.44) ; if this is the case, we take the mid-point of the interval as the median. Show that one may characterize the median as a number at which the function achieves its minimum value; this is therefore . Hint: Although the assertion is true in general, show it only for a continuous probability law. Show, and use the fact, that for any number
2.11 . The mode of a continuous or discrete probability law . For a continuous probability law with probability density function a mode of the probability law is defined as a number at which the probability density has a relative maximum; assuming that the probability density function is twice differentiable, a point is a mode if
2.12 . The interquartile range of a probability law . Possible measures exist of the dispersion of a probability distribution, in addition to the variance, which one may consider (especially if the variance is infinite). The most important of these is the interquartile range of the probability law, defined as follows: for any number , between 0 and 1, define the percentile of the probability law as the number satisfying . Thus is the projection on the -axis of the point in the -plane at which the line intersects the curve . The 0.5 percentile is usually called the median. The interquartile range, defined as the difference , may be taken as a measure of the dispersion of the probability law.
(i) Show that the ratio of the interquartile range to the standard deviation is (a), for the normal probability law with parameters and , (b), for the exponential probability law with parameter , (c), for the uniform probability law over the interval to .
(ii) Show that the Cauchy probability law specified by the probability density function possesses neither a mean nor a variance. However, it possesses a median and an interquartile range given by .
Exercises
In exercises 2.1 to 2.7, compute the mean and variance of the probability law specified by the probability density function, probability mass function, or distribution function given.
2.1 .
Answer
Mean (i) , (ii) 0 , (iii) ; variance (i) , (ii) , (iii) .
2.2 .
2.3 .
Answer
Mean (i) does not exist, (ii) 0, (iii) 0; variance (i) does not exist, (ii) 3, (iii) 1.
2.4 .
2.5 .
Answer
Mean (i) , (ii) 4 (iii) 4; variance (i) , (ii) , (iii) .
2.6 .
2.7 .
Answer
Mean (i) , (ii) ; variance (i) , (ii) .
2.8 . Compute the means and variances of the probability laws obeyed by the numerical valued random phenomena described in exercise 4.1 of Chapter 4.
2.9 . For what values of does the probability law, specified by the following probability density function, possess (i) a finite mean, (ii) a finite variance:
Answer
(i) ; (ii) .
- For the benefit of the reader acquainted with the theory of Lebesgue integration, let it be remarked that if the integral in (2.3) is defined as an integral in the sense of Lebesgue then the notion of expectation may be defined for a Borel function . ↩︎