Índice
- 16.1 INTRODUÇÃO
- 16.2 AULA
- 16.3 EXEMPLOS
- 16.4 ILUSTRAÇÕES
- 16.4.1 Potência a Partir do Potencial: Uma Conexão com a Regra da Cadeia
- 16.4.2 Caos via Derivadas: Expoentes de Lyapunov e Entropia em Mapas Iterados
- 16.4.3 Equações de Hamilton e Conservação de Energia
- 16.4.4 A Regra da Cadeia Desbloqueia Inversas
- 16.4.5 Diferenciação Implícita: Encontrando a Inclinação Misteriosa
- 16.4.6 Soluções Garantidas: O Teorema da Função Implícita
16.1 INTRODUÇÃO
16.1.1 Construindo Funções Complexas a Partir de Funções Básicas
No cálculo, podemos construir, a partir de funções básicas, funções mais gerais. Uma possibilidade é somar funções como . Outra possibilidade é multiplicar funções como . Uma terceira possibilidade é compor funções como . A composição de funções é não comutativa: . De fato, temos que é completamente diferente de .
16.1.2 A Regra da Cadeia: De Uma Variável para Dimensões Superiores
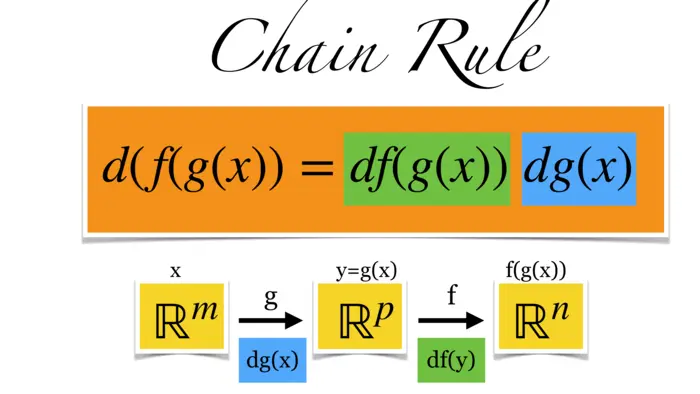
Como podemos expressar a taxa de variação de uma função composta em termos das funções básicas que a compõem? Para a soma de duas funções, temos a regra da adição (f+g)^{\prime}(x)=f^{\prime}(x)+g^{\prime}(x), para a multiplicação temos a regra do produto (f g)^{\prime}(x)=f^{\prime}(x) g(x)+f(x) g(x). Geralmente escrevemos apenas (f+g)^{\prime}=f^{\prime}+g^{\prime} ou (f g)^{\prime}=f^{\prime} g+f g^{\prime} e nem sempre escrevemos o argumento. Como você sabe do cálculo de uma variável, a derivada da função composta é dada pela regra da cadeia. Isto é (f \circ g)^{\prime}=f^{\prime}(g) g^{\prime}. Escrevendo com mais detalhes com o argumento, podemos escrever \frac{d}{d x} f(g(x))=\frac{d}{d x} f^{\prime}(g(x)) g^{\prime}(x). Generalizamos isso aqui para dimensões superiores. Em vez de simplesmente escrevemos . Esta é a matriz Jacobiana que conhecemos. Agora, a mesma regra vale como antes e isso é chamado de regra da cadeia em dimensões superiores. No lado direito, temos o produto matricial de duas matrizes.
16.1.3 Dimensões e a Regra da Cadeia
Vejamos por que isso faz sentido em termos de dimensões: e , então e e que é o mesmo tipo de matriz que porque mapeia de modo que também . O nome regra da cadeia vem porque ela lida com funções que estão encadeadas.
16.2 AULA
16.2.1 A Regra da Cadeia Multivariável
Dada uma função diferenciável , sua derivada em é a matriz Jacobiana . Se é outra função com , podemos combiná-las e formar . As matrizes e combinam-se no produto matricial em um ponto. Esta matriz está em . A regra da cadeia multivariável é:
Teorema 1. .
16.2.2 Funções Escalares e o Gradiente
Para , o caso do cálculo de uma variável, temos d f(x)=f^{\prime}(x) e (f \circ r)^{\prime}(x)=f^{\prime}(r(x)) r^{\prime}(x). Em geral, é agora uma matriz em vez de um número. Verificando uma única entrada da matriz, reduzimos ao caso . Nesse caso, é uma função escalar. Enquanto é um vetor linha, definimos o vetor coluna Se é uma curva, escrevemos r^{\prime}(t)= [x_{1}^{\prime}(t), \cdots, x_{p}^{\prime}(t)]^{T} em vez de . O símbolo também é chamado de "nabla".1 O caso especial é:
Teorema 2. \frac{d}{d t} f(r(t))=\nabla f(r(t)) \cdot r^{\prime}(t).
Demonstração. é o limite de \begin{aligned} & \big[f\big(x_{1}(t+h), x_{2}(t+h), \ldots, x_{p}(t+h)\big)-f\big(x_{1}(t), x_{2}(t), \ldots, x_{p}(t)\big)\big] / h \\ = & \big[f\big(x_{1}(t+h), x_{2}(t+h), \ldots, x_{p}(t+h)\big)-f\big(x_{1}(t), x_{2}(t+h), \ldots, x_{p}(t+h)\big)\big] / h \\ + & \big[f\big(x_{1}(t), x_{2}(t+h), \ldots, x_{p}(t+h)\big)-f\big(x_{1}(t), x_{2}(t), \ldots, x_{p}(t+h)\big)\big] / h+\cdots \\ + & \big[f\big(x_{1}(t), x_{2}(t), \ldots, x_{p}(t+h)\big)-f\big(x_{1}(t), x_{2}(t), \ldots, x_{p}(t)\big)\big] / h \end{aligned} que é (regra da cadeia 1D) no limite a soma f_{x_{1}}(x) x_{1}^{\prime}(t)+\cdots+f_{x_{p}}(x) x_{p}^{\prime}(t).
Demonstração do caso geral: Seja . A entrada da matriz Jacobiana é . O caso da entrada reduz-se com e ao caso em que é uma curva e é uma função escalar. Este é o caso que já provamos. ◻
16.3 EXEMPLOS
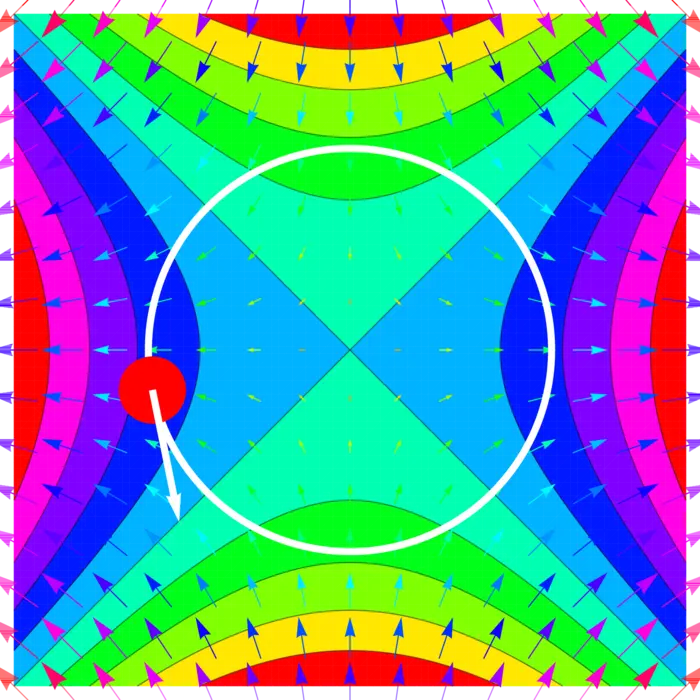
Exemplo 1. Suponha que uma joaninha caminhe sobre um círculo e seja a temperatura na posição , então é a taxa de variação da temperatura. Podemos escrever Agora, . O gradiente de e a velocidade são \nabla f(x, y)=\left[\begin{array}{r}2 x \\ -2 y\end{array}\right], \quad r^{\prime}(t)=\left[\begin{array}{r}-\sin (t) \\ \cos (t)\end{array}\right]. Agora \begin{aligned} \nabla f(r(t)) \cdot r^{\prime}(t)&=\left[\begin{array}{r} 2 \cos (t) \\ -2 \sin (t) \end{array}\right] \cdot\left[\begin{array}{r} -\sin (t) \\ \cos (t) \end{array}\right]\\ &=-4 \cos (t) \sin (t)\\ &=-2 \sin (2 t). \end{aligned}
16.4 ILUSTRAÇÕES
16.4.1 Potência a Partir do Potencial: Uma Conexão com a Regra da Cadeia
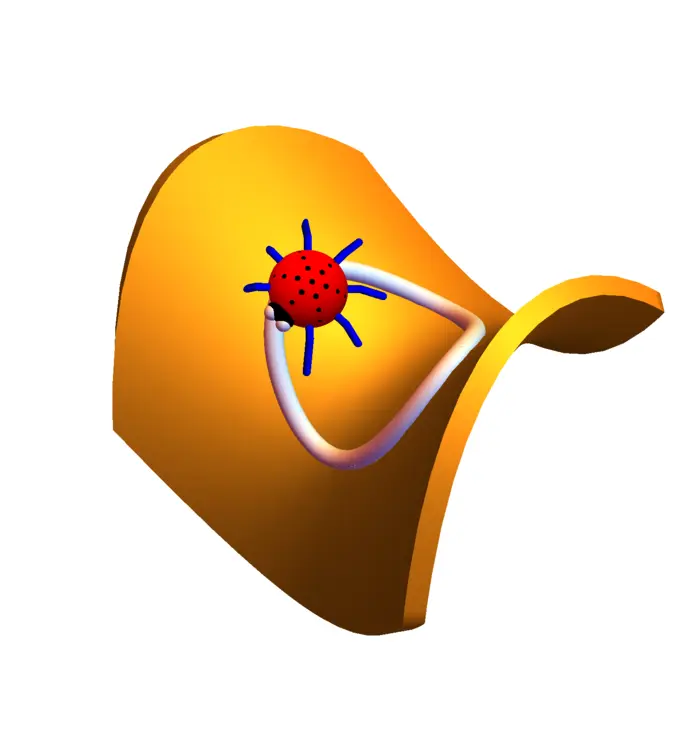
O caso é extremamente importante. A regra da cadeia \nabla f(r(t)) \cdot r^{\prime}(t) diz que a taxa de variação da energia potencial na posição é o produto escalar da força no ponto e a velocidade com a qual nos movemos. O lado direito é potência força vezes velocidade. Usaremos isso mais tarde no teorema fundamental das integrais de linha.
16.4.2 Caos via Derivadas: Expoentes de Lyapunov e Entropia em Mapas Iterados
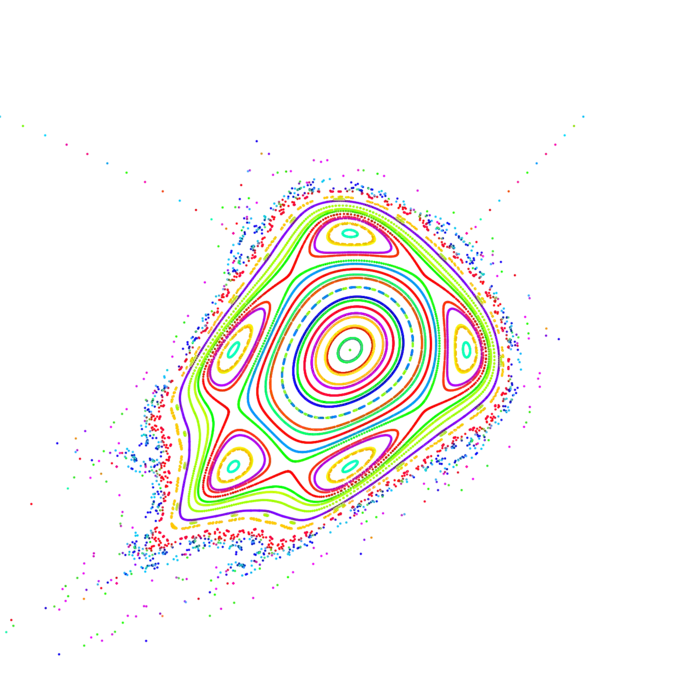
Se , então é novamente um mapa de para . Também podemos iterar um mapa como A derivada é, pela regra da cadeia, o produto de matrizes Jacobianas. O número é chamado de expoente de Lyapunov do mapa no ponto . Ele mede a quantidade de caos, a "dependência sensível das condições iniciais" de . Esses números são difíceis de estimar matematicamente. Já para exemplos simples como o mapa de Chirikov pode-se medir entropia positiva . Uma conjectura de Sinai afirma que a entropia do mapa é positiva para grande. Medições mostram que essa entropia satisfaz . A conjectura ainda está em aberto.2
16.4.3 Equações de Hamilton e Conservação de Energia
Se é uma função chamada de Hamiltoniana e x^{\prime}(t)=H_{y}(x, y), y^{\prime}(t)= , então . Isso pode ser interpretado como conservação de energia. Vemos que uma equação diferencial Hamiltoniana sempre preserva a energia. Para o pêndulo, , temos x^{\prime}=y, y^{\prime}=-\sin (x) ou x^{\prime \prime}=-\sin (x).

16.4.4 A Regra da Cadeia Desbloqueia Inversas
A regra da cadeia é útil para obter derivadas de funções inversas. Como \begin{aligned} 1=\frac{d}{d x} x&=\frac{d}{d x} \sin (\arcsin (x))\\ &=\cos (\arcsin (x)) \arcsin ^{\prime}(x) \end{aligned} que então fornece \begin{aligned} \arcsin ^{\prime}(x)&=1 / \sqrt{1-\sin ^{2}(\arcsin (x))}\\ &=1 / \sqrt{1-x^{2}}. \end{aligned}
16.4.5 Diferenciação Implícita: Encontrando a Inclinação Misteriosa
Suponha que seja uma curva. Não podemos resolver para . Ainda assim, podemos assumir . A diferenciação usando a regra da cadeia fornece f_{x}(x, y(x))+f_{y}(x, y(x)) y^{\prime}(x)=0. Portanto y^{\prime}(x)=-\frac{f_{x}(x, y(x))}{f_{y}(x, y(x))} No exemplo acima, o ponto está sobre a curva. Agora e . Então, g^{\prime}(1)=-7 / 6. Isso é chamado de diferenciação implícita. Poderíamos calcular com ela a derivada de uma função que não era conhecida.
16.4.6 Soluções Garantidas: O Teorema da Função Implícita
O teorema da função implícita garante que uma função implícita diferenciável existe perto de uma raiz de uma função diferenciável .
Teorema 3. Se , existe e uma função com .
Prova. Seja tão pequeno que, para fixo, a função tenha a propriedade e e h^{\prime}(y) \neq 0 em . O teorema do valor intermediário para agora garante uma raiz única de próxima a . A fórmula da regra da cadeia acima então garante que, para , o quociente diferencial escrito para tem limite . ◻
P.S. Podemos obter a raiz de aplicando passos de Newton T(y)=y-h(y) / h^{\prime}(y). Taylor (visto na próxima aula) mostra que o erro é elevado ao quadrado a cada passo. O passo de Newton também funciona em dimensões arbitrárias. Pode-se provar o teorema da função implícita simplesmente estabelecendo que Id é uma contração e então usar o teorema do ponto fixo de Banach para obter um ponto fixo de , que é uma raiz de .

As unidades 16 e 17 são ensinadas juntas na quarta-feira. A tarefa está toda na unidade 17.
- A etimologia diz que o símbolo é inspirado em uma harpa egípcia ou fenícia.↩︎
- Para gerar órbitas, veja http://www.math.harvard.edu/k̃nill/technology/chirikov/.↩︎