Table des matières
- 16.1 INTRODUCTION
- 16.2 COURS
- 16.3 EXEMPLES
- 16.4 ILLUSTRATIONS
- 16.4.1 Puissance à partir du potentiel : une connexion par la règle de la chaîne
- 16.4.2 Chaos via les dérivées : exposants de Lyapunov et entropie dans les applications itérées
- 16.4.3 Équations de Hamilton et conservation de l'énergie
- 16.4.4 La règle de la chaîne déverrouille les inverses
- 16.4.5 Différenciation implicite : trouver la pente mystérieuse
- 16.4.6 Solutions garanties : le théorème des fonctions implicites
16.1 INTRODUCTION
16.1.1 Construction de fonctions complexes à partir de fonctions de base
En calcul, nous pouvons construire des fonctions plus générales à partir de fonctions de base. Une possibilité est d'additionner des fonctions comme . Une autre possibilité est de multiplier des fonctions comme . Une troisième possibilité est de composer des fonctions comme . La composition de fonctions est non commutative : . En effet, nous avons qui est complètement différent de .
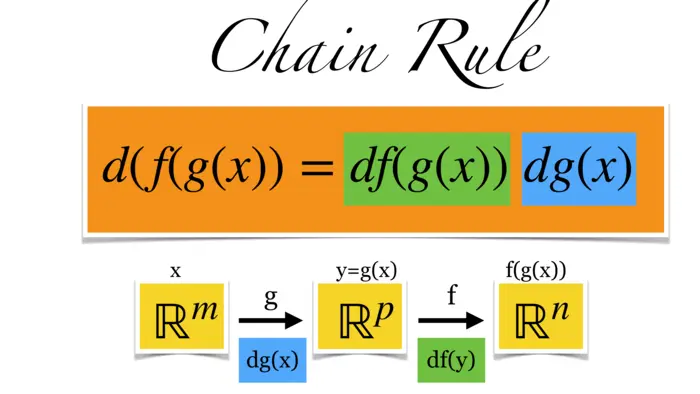
16.1.2 La règle de la chaîne : d'une variable à des dimensions supérieures
Comment pouvons-nous exprimer le taux de variation d'une fonction composée en termes des fonctions de base qui la constituent ? Pour la somme de deux fonctions, nous avons la règle d'addition (f+g)^{\prime}(x)=f^{\prime}(x)+g^{\prime}(x), pour la multiplication nous avons la règle du produit (f g)^{\prime}(x)=f^{\prime}(x) g(x)+f(x) g(x). Nous écrivons habituellement simplement (f+g)^{\prime}=f^{\prime}+g^{\prime} ou (f g)^{\prime}=f^{\prime} g+f g^{\prime} et n'écrivons pas toujours l'argument. Comme vous le savez du calcul à une variable, la dérivée de la fonction composée est donnée par la règle de la chaîne. C'est (f \circ g)^{\prime}=f^{\prime}(g) g^{\prime}. Écrit plus en détail avec l'argument, nous pouvons écrire \frac{d}{d x} f(g(x))=\frac{d}{d x} f^{\prime}(g(x)) g^{\prime}(x). Nous généralisons cela ici aux dimensions supérieures. Au lieu de nous écrivons simplement . C'est la matrice jacobienne que nous connaissons. Maintenant, la même règle s'applique comme avant et cela s'appelle la règle de la chaîne en dimensions supérieures. Du côté droit, nous avons le produit matriciel de deux matrices.
16.1.3 Dimensions et la règle de la chaîne
Voyons pourquoi cela a du sens en termes de dimensions : et , alors et et qui est le même type de matrice que parce que envoie de sorte que aussi . Le nom règle de la chaîne vient du fait qu'elle traite de fonctions qui sont enchaînées ensemble.
16.2 COURS
16.2.1 La règle de la chaîne multivariable
Étant donnée une fonction différentiable , sa dérivée en est la matrice jacobienne . Si est une autre fonction avec , nous pouvons les combiner et former . Les matrices et se combinent en le produit matriciel en un point. Cette matrice est dans . La règle de la chaîne multivariable est :
Théorème 1. .
16.2.2 Fonctions scalaires et le gradient
Pour , le cas du calcul à une variable, nous avons d f(x)=f^{\prime}(x) et (f \circ r)^{\prime}(x)=f^{\prime}(r(x)) r^{\prime}(x). En général, est maintenant une matrice plutôt qu'un nombre. En vérifiant une seule entrée de la matrice, nous nous réduisons au cas . Dans ce cas, est une fonction scalaire. Alors que est un vecteur ligne, nous définissons le vecteur colonne Si est une courbe, nous écrivons r^{\prime}(t)= [x_{1}^{\prime}(t), \cdots, x_{p}^{\prime}(t)]^{T} au lieu de . Le symbole est aussi appelé "nabla".1 Le cas spécial est :
Théorème 2. \frac{d}{d t} f(r(t))=\nabla f(r(t)) \cdot r^{\prime}(t).
Preuve. est la limite de \begin{aligned} & \big[f\big(x_{1}(t+h), x_{2}(t+h), \ldots, x_{p}(t+h)\big)-f\big(x_{1}(t), x_{2}(t), \ldots, x_{p}(t)\big)\big] / h \\ = & \big[f\big(x_{1}(t+h), x_{2}(t+h), \ldots, x_{p}(t+h)\big)-f\big(x_{1}(t), x_{2}(t+h), \ldots, x_{p}(t+h)\big)\big] / h \\ + & \big[f\big(x_{1}(t), x_{2}(t+h), \ldots, x_{p}(t+h)\big)-f\big(x_{1}(t), x_{2}(t), \ldots, x_{p}(t+h)\big)\big] / h+\cdots \\ + & \big[f\big(x_{1}(t), x_{2}(t), \ldots, x_{p}(t+h)\big)-f\big(x_{1}(t), x_{2}(t), \ldots, x_{p}(t)\big)\big] / h \end{aligned} ce qui est (règle de la chaîne 1D) à la limite la somme f_{x_{1}}(x) x_{1}^{\prime}(t)+\cdots+f_{x_{p}}(x) x_{p}^{\prime}(t).
Preuve du cas général : Soit . L'entrée de la matrice jacobienne est . Le cas de l'entrée se réduit avec et au cas où est une courbe et est une fonction scalaire. C'est le cas que nous avons déjà prouvé. ◻
16.3 EXEMPLES
Exemple 1. Supposons qu'une coccinelle marche sur un cercle et que soit la température à la position , alors est le taux de variation de la température. Nous pouvons écrire Maintenant, . Le gradient de et la vitesse sont \nabla f(x, y)=\left[\begin{array}{r}2 x \\ -2 y\end{array}\right], \quad r^{\prime}(t)=\left[\begin{array}{r}-\sin (t) \\ \cos (t)\end{array}\right]. Maintenant \begin{aligned} \nabla f(r(t)) \cdot r^{\prime}(t)&=\left[\begin{array}{r} 2 \cos (t) \\ -2 \sin (t) \end{array}\right] \cdot\left[\begin{array}{r} -\sin (t) \\ \cos (t) \end{array}\right]\\ &=-4 \cos (t) \sin (t)\\ &=-2 \sin (2 t). \end{aligned}
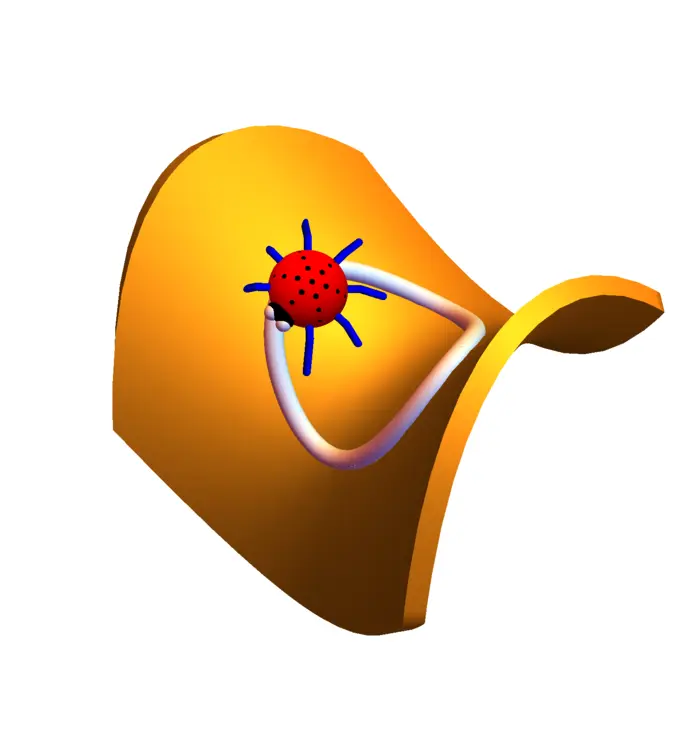
16.4 ILLUSTRATIONS
16.4.1 Puissance à partir du potentiel : une connexion par la règle de la chaîne
Le cas est extrêmement important. La règle de la chaîne \nabla f(r(t)) \cdot r^{\prime}(t) dit que le taux de variation de l'énergie potentielle à la position est le produit scalaire de la force au point et de la vitesse avec laquelle nous nous déplaçons. Le côté droit est la puissance force fois vitesse. Nous utiliserons cela plus tard dans le théorème fondamental des intégrales curvilignes.
16.4.2 Chaos via les dérivées : exposants de Lyapunov et entropie dans les applications itérées
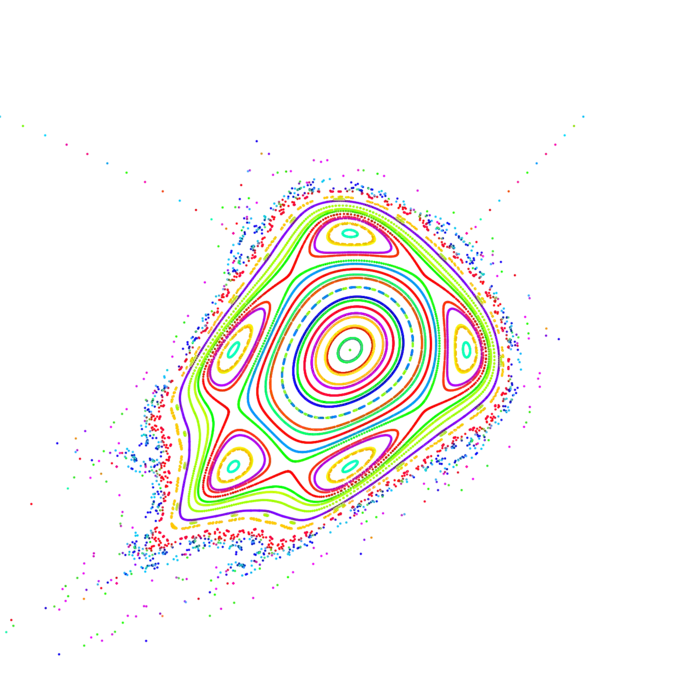
Si , alors est à nouveau une application de vers . Nous pouvons aussi itérer une application comme La dérivée est par la règle de la chaîne le produit de matrices jacobiennes. Le nombre est appelé l'exposant de Lyapunov de l'application au point . Il mesure la quantité de chaos, la "dépendance sensible aux conditions initiales" de . Ces nombres sont difficiles à estimer mathématiquement. Déjà pour des exemples simples comme l'application de Chirikov on peut mesurer une entropie positive . Une conjecture de Sinai dit que l'entropie de l'application est positive pour de grands . Des mesures montrent que cette entropie satisfait . La conjecture est toujours ouverte.2
16.4.3 Équations de Hamilton et conservation de l'énergie
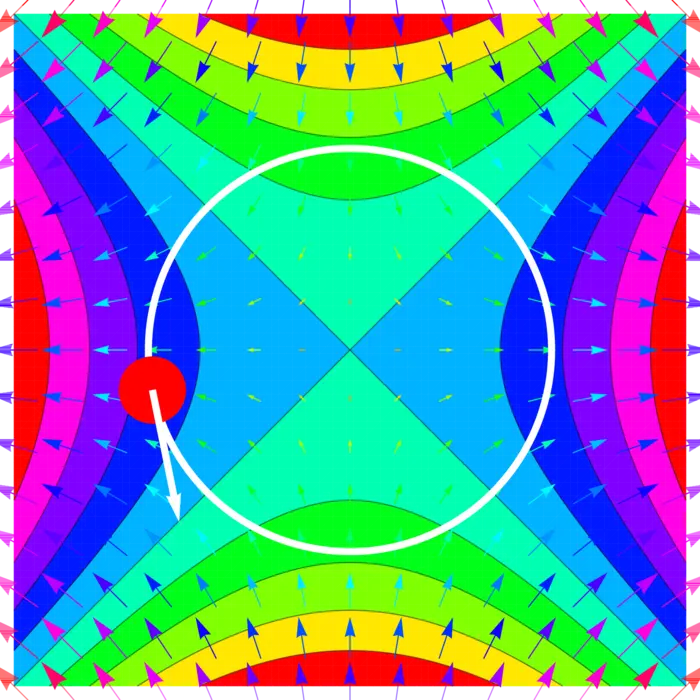
Si est une fonction appelée le hamiltonien et x^{\prime}(t)=H_{y}(x, y), y^{\prime}(t)= , alors . Cela peut être interprété comme la conservation de l'énergie. Nous voyons qu'une équation différentielle hamiltonienne préserve toujours l'énergie. Pour le pendule, , nous avons x^{\prime}=y, y^{\prime}=-\sin (x) ou x^{\prime \prime}=-\sin (x).

16.4.4 La règle de la chaîne déverrouille les inverses
La règle de la chaîne est utile pour obtenir les dérivées des fonctions inverses. Comme \begin{aligned} 1=\frac{d}{d x} x&=\frac{d}{d x} \sin (\arcsin (x))\\ &=\cos (\arcsin (x)) \arcsin ^{\prime}(x) \end{aligned} ce qui donne alors \begin{aligned} \arcsin ^{\prime}(x)&=1 / \sqrt{1-\sin ^{2}(\arcsin (x))}\\ &=1 / \sqrt{1-x^{2}}. \end{aligned}
16.4.5 Différenciation implicite : trouver la pente mystérieuse
Supposons que soit une courbe. Nous ne pouvons pas résoudre pour . Néanmoins, nous pouvons supposer . La différenciation en utilisant la règle de la chaîne donne f_{x}(x, y(x))+f_{y}(x, y(x)) y^{\prime}(x)=0. Par conséquent y^{\prime}(x)=-\frac{f_{x}(x, y(x))}{f_{y}(x, y(x))} Dans l'exemple ci-dessus, le point est sur la courbe. Maintenant et . Donc, g^{\prime}(1)=-7 / 6. Cela s'appelle la différenciation implicite. Nous pourrions calculer avec elle la dérivée d'une fonction qui n'était pas connue.
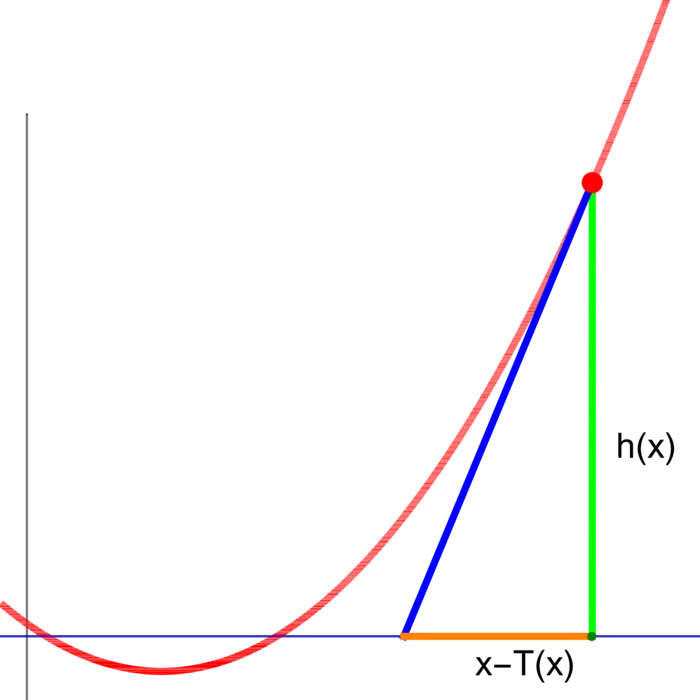
16.4.6 Solutions garanties : le théorème des fonctions implicites
Le théorème des fonctions implicites assure qu'une fonction implicite différentiable existe près d'une racine d'une fonction différentiable .
Théorème 3. Si , il existe et une fonction avec .
Preuve. Soit si petit que pour fixé, la fonction ait la propriété et et h^{\prime}(y) \neq 0 dans . Le théorème des valeurs intermédiaires pour assure alors une unique racine de près de . La formule de la règle de dérivation en chaîne ci-dessus assure alors que pour , le quotient différentiel écrit pour a une limite . ◻
P.-S. On peut obtenir la racine de en appliquant des étapes de Newton T(y)=y-h(y) / h^{\prime}(y). Taylor (vu au prochain cours) montre que l'erreur est élevée au carré à chaque étape. L'étape de Newton fonctionne aussi en dimensions arbitraires. On peut prouver le théorème des fonctions implicites en établissant simplement que Id est une contraction, puis en utilisant le théorème du point fixe de Banach pour obtenir un point fixe de qui est une racine de .

Les unités 16 et 17 sont enseignées ensemble le mercredi. Les devoirs sont tous dans l'unité 17.
- L'étymologie indique que le symbole est inspiré d'une harpe égyptienne ou phénicienne.↩︎
- Pour générer des orbites, voir http://www.math.harvard.edu/k̃nill/technology/chirikov/.↩︎