Table des matières
20.1 INTRODUCTION
20.1.1 Gradients pour des solutions optimales avec contraintes
Il n’y a rarement de « repas gratuit ». Si nous voulons maximiser une quantité, nous devons souvent travailler avec des contraintes. Les obstacles peuvent nous empêcher de modifier les paramètres arbitrairement. Le gradient peut toujours être utilisé comme principe directeur. Bien que nous ne puissions pas obtenir que soit nul, nous pouvons chercher des points où le gradient est perpendiculaire à la contrainte. Cela nous donne un point optimal sous la contrainte. Si vous randonnez sur un chemin de montagne, vous atteignez souvent un maximum local sans être au sommet de la montagne. Ce qui se produit en de tels points est que est perpendiculaire à la courbe, ce qui signifie que est parallèle à .
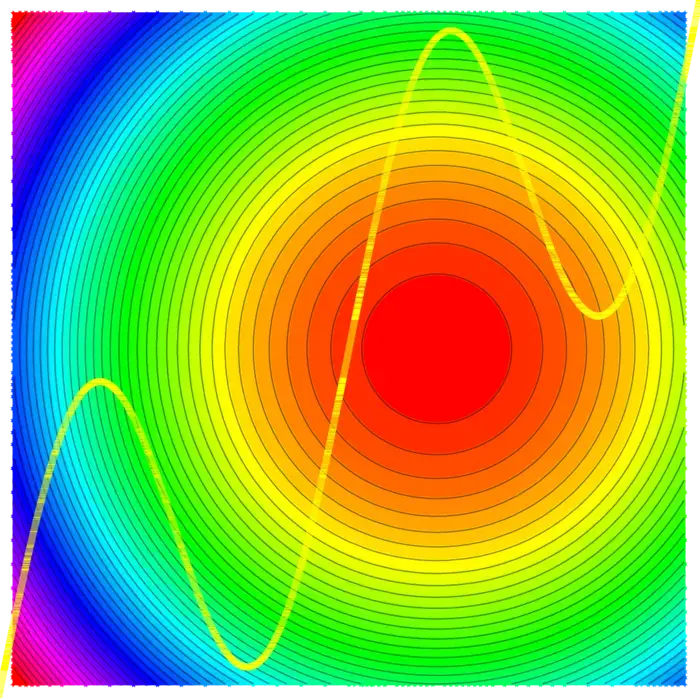
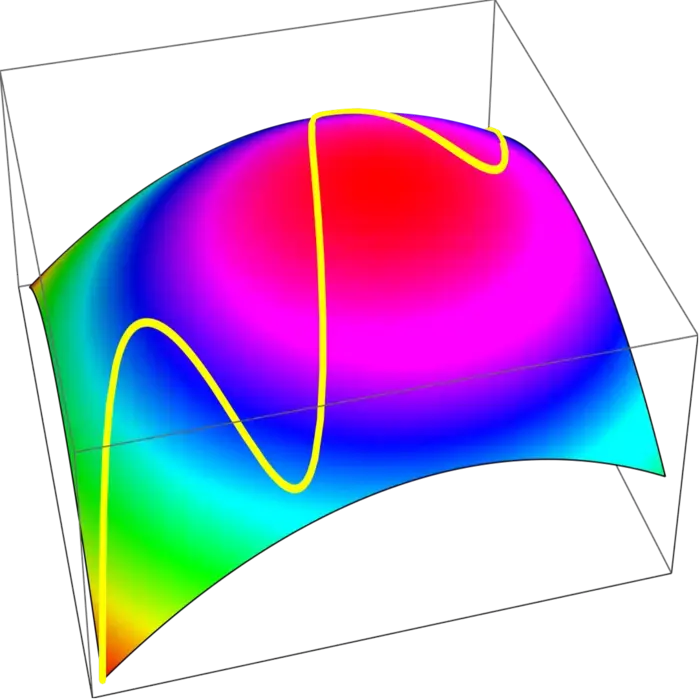
20.1.2 La magie de Lagrange : plusieurs contraintes, une solution
La méthode de Lagrange est bien plus générale. Nous pouvons travailler avec un nombre arbitraire de contraintes et utiliser le même principe. Le gradient de est alors perpendiculaire à la surface de contrainte, ce qui signifie qu’il est une combinaison linéaire des gradients de toutes les contraintes : ce sont équations car les vecteurs ont composantes. Avec les équations , nous avons équations pour variables , .
20.2 COURS
20.2.1 Trouver le maximum dans des espaces confinés
Si nous voulons maximiser une fonction sous la contrainte alors les gradients de et de importent. Nous appelons deux vecteurs , parallèles si ou pour un réel . Le vecteur nul est parallèle à tout. Voici une variante de Fermat :
Théorème 1. Si est un maximum de sous la contrainte , alors et sont parallèles.
Preuve. Par l'absurde : supposons que et ne sont pas parallèles et que est un maximum local. Soit le plan tangent à en . Puisque n’est pas perpendiculaire à nous pouvons le projeter sur pour obtenir un vecteur non nul dans qui n’est pas perpendiculaire à . En réalité, l’angle entre et est aigu de sorte que . Prenons une courbe dans avec et r^{\prime}(0)=v. Nous avons \begin{aligned} d / d t f(r(0))&=\nabla f(r(0)) \cdot r^{\prime}(0)\\ &=|\nabla f(x_{0})||v| \cos (\alpha)\\ &>0. \end{aligned} Par approximation linéaire, nous savons que pour assez petit. Ceci est une contradiction avec le fait que était maximale en sur . ◻
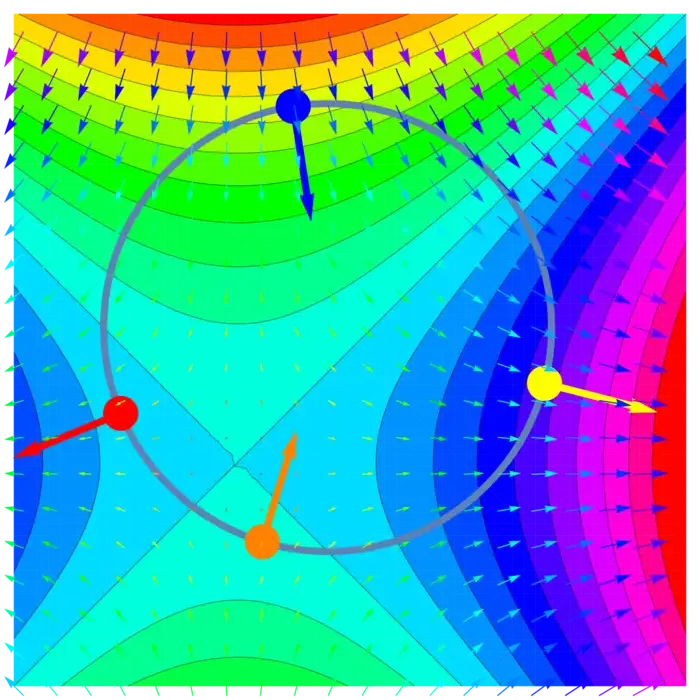
20.2.2 Exploration des multiplicateurs de Lagrange et conditions nécessaires
Cela implique immédiatement : (distinguer et )
Théorème 2. Pour un maximum de sur , soit les équations de Lagrange , sont vérifiées, soit alors , .
Pour des fonctions de deux variables, cela signifie que nous devons résoudre un système de trois équations à trois inconnues : \begin{aligned} f_{x}(x_{0}, y_{0}) & =\lambda g_{x}(x_{0}, y_{0}) \\ f_{y}(x_{0}, y_{0}) & =\lambda g_{y}(x_{0}, y_{0}) \\ g(x, y) & =c \end{aligned}
20.2.3 Trouver le véritable maximum
Pour trouver un maximum, résoudre les équations de Lagrange et ajouter une liste de points critiques de sur la contrainte. Ensuite, choisir un point où est maximale parmi tous les points. Nous ne nous soucions pas du test de la dérivée seconde. Mais voici un énoncé possible : pour tout perpendiculaire à , alors est un maximum local.
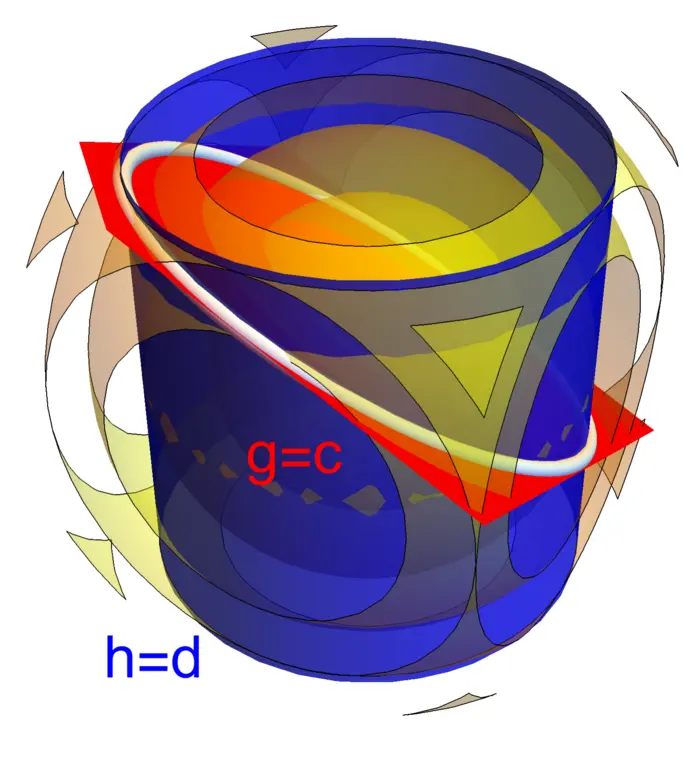
Bien sûr, les cas des maxima et minima sont analogues. Si a un maximum sur , alors a un minimum sur . Nous pouvons avoir un maximum de sous une contrainte lisse sans que les équations de Lagrange soient satisfaites. Un exemple est et montré dans la Figure (20.3).
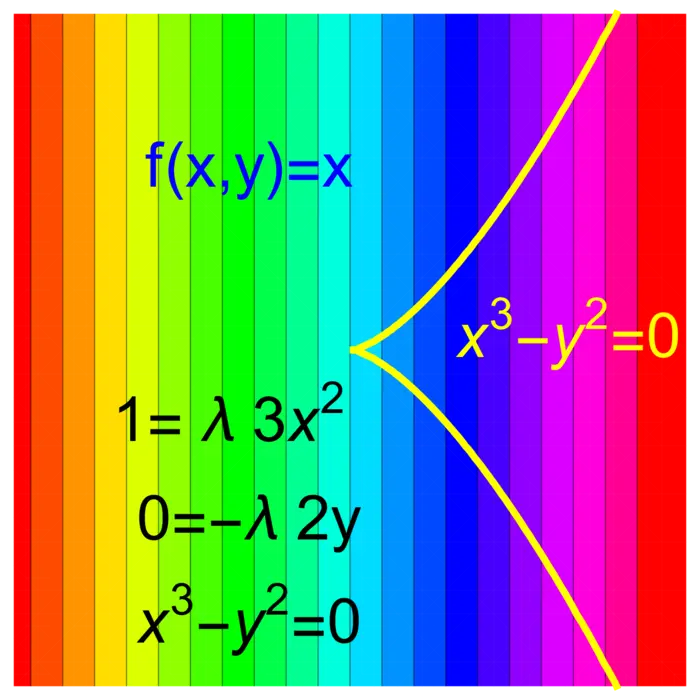
20.2.4 L'ascension de Lagrange : maximiser avec plusieurs contraintes
La méthode de Lagrange peut maximiser des fonctions sous plusieurs contraintes. Montrons cela dans le cas d’une fonction de trois variables et deux contraintes et . L’analogue du principe de Fermat est qu’en un maximum de , le gradient de est dans le plan engendré par et . Cela conduit aux équations de Lagrange pour inconnues . \begin{aligned} f_{x}(x_{0}, y_{0}, z_{0}) & =\lambda g_{x}(x_{0}, y_{0}, z_{0})+\mu h_{x}(x_{0}, y_{0}, z_{0}) \\ f_{y}(x_{0}, y_{0}, z_{0}) & =\lambda g_{y}(x_{0}, y_{0}, z_{0})+\mu h_{y}(x_{0}, y_{0}, z_{0}) \\ f_{z}(x_{0}, y_{0}, z_{0}) & =\lambda g_{z}(x_{0}, y_{0}, z_{0})+\mu h_{z}(x_{0}, y_{0}, z_{0}) \\ g(x, y, z) & =c \\ h(x, y, z) & =d \end{aligned}
Par exemple, si \begin{aligned} f(x, y, z)&=x^{2}+y^{2}+z^{2},\\ g(x, y, z)&=x^{2}+y^{2}=1,\\ h(x, y, z)&=x+y+z=4, \end{aligned} alors nous trouvons des points sur l’ellipse , avec une distance minimale ou maximale à .
20.3 EXEMPLES
Exemple 1. Problème : Minimiser sous la contrainte .
Solution : Les équations de Lagrange sont , . Si alors . Si nous pouvons diviser la deuxième équation par et obtenir , ce qui montre à nouveau . Le point , est la seule solution.
Exemple 2. Problème : Quelle canette de soda cylindrique de hauteur et de rayon a une surface minimale pour un volume fixé ?
Solution : Nous avons et . Avec , , vous devez optimiser sous la contrainte . Nous le ferons en classe.
Exemple 3. Problème : Si est la probabilité qu’un dé montre , alors nous avons . Ce vecteur est appelé une distribution de probabilité. L’entropie de Shannon de est définie comme \begin{aligned} S(p)&=-\sum_{i=1}^{6} p_{i} \log (p_{i})\\ &=-p_{1} \log (p_{1})-p_{2} \log (p_{2})-\cdots-p_{6} \log (p_{6}) \end{aligned}
Trouver la distribution qui maximise l’entropie .
Solution : Les équations de Lagrange sont d’où nous tirons . La dernière équation fixe de sorte que . C’est le dé équitable qui a l’entropie maximale. L’entropie maximale signifie le moindre contenu d’information.
Exemple 4. Supposons que la probabilité qu’un système physique ou chimique soit dans un état est et que l’énergie de l’état est . La nature minimise l’énergie libre si les énergies sont fixées. La distribution de probabilité satisfaisant qui minimise l’énergie libre est appelée une distribution de Gibbs. Trouver cette distribution en général si les sont donnés.
Solution : Les équations de Lagrange sont , ou , où . La contrainte donne de sorte que . La solution de Gibbs est .1
Exemple 5. Si est une fonction quadratique sur et est linéaire, c’est-à-dire avec et si la contrainte est linéaire , alors et . Appelons . Les équations de Lagrange sont alors , . Nous voyons en général que pour quadratique et linéaire, nous aboutissons à un système d’équations linéaires.
Exemple 6. En lien avec la remarque précédente, voici l’observation suivante. Il est souvent possible de réduire le problème de Lagrange à un problème sans contrainte. C’est un point de vue souvent adopté en économie. Regardons cela en dimension , où nous extremisons sous la contrainte . Définissons . Les équations de Lagrange pour sont maintenant équivalentes à en trois dimensions.
EXERCICES
Exercice 1. Trouvez le panier cylindrique ouvert en haut qui a le plus grand volume pour une aire fixée . Si est le rayon et la hauteur, nous devons maximiser sous la contrainte Utilisez la méthode des multiplicateurs de Lagrange.
Exercice 2. Étant donnée une matrice symétrique , nous considérons la fonction et cherchons les extrema de sous la contrainte . Cela conduit à l'équation Une solution est appelée un vecteur propre. La constante de Lagrange est une valeur propre. Trouvez les solutions de , si est une matrice , où Résolvez ensuite le problème avec , , , .
Exercice 3. Quelle pyramide de hauteur sur un carré dont l'aire de surface est a un volume maximal ? En utilisant de nouvelles variables et en multipliant par une constante, on obtient le problème équivalent de maximiser sous la contrainte Utilisez ces dernières variables.
Exercice 4. Motivés par le film Disney « Raiponce », nous voulons construire une montgolfière avec un maillage cuboïde de dimensions , , qui, avec les renforts du haut et du bas, utilise des câbles de longueur totale Trouvez le ballon de volume maximal .
Exercice 5. Une balle solide composée d'une demi-sphère et d'un cylindre a un volume et une aire de surface . Le Docteur Manhattan conçoit une balle de volume fixé et d'aire minimale. Avec et , il minimise donc sous la contrainte Utilisez la méthode de Lagrange pour trouver un minimum local de sous la contrainte .
Annexe : Illustration de données : Cobb Douglas
20.3.1 Cobb-Douglas : Une formule pour la croissance économique
Le mathématicien et économiste Charles W. Cobb du Amherst College et l'économiste et politicien Paul H. Douglas, qui enseignait également à Amherst, ont trouvé en 1928 empiriquement une formule qui correspond à la production totale d'un système économique en fonction de l'investissement en capital et du travail . Les deux auteurs ont utilisé des variables logarithmiques et supposé la linéarité pour trouver . Voici les données normalisées de sorte que la valeur pour l'année 1899 soit .
| Année | |||
|---|---|---|---|
| 1899 | 100 | 100 | 100 |
| 1900 | 107 | 105 | 101 |
| 1901 | 114 | 110 | 112 |
| 1902 | 122 | 118 | 122 |
| 1903 | 131 | 123 | 124 |
| 1904 | 138 | 116 | 122 |
| 1905 | 149 | 125 | 143 |
| 1906 | 163 | 133 | 152 |
| 1907 | 176 | 138 | 151 |
| 1908 | 185 | 121 | 126 |
| 1909 | 198 | 140 | 155 |
| 1910 | 208 | 144 | 159 |
| 1911 | 216 | 145 | 153 |
| 1912 | 226 | 152 | 177 |
| 1913 | 236 | 154 | 184 |
| 1914 | 244 | 149 | 169 |
| 1915 | 266 | 154 | 189 |
| 1916 | 298 | 182 | 225 |
| 1917 | 335 | 196 | 227 |
| 1918 | 366 | 200 | 223 |
| 1919 | 387 | 193 | 218 |
| 1920 | 407 | 193 | 231 |
| 1921 | 417 | 147 | 179 |
| 1922 | 431 | 161 | 240 |
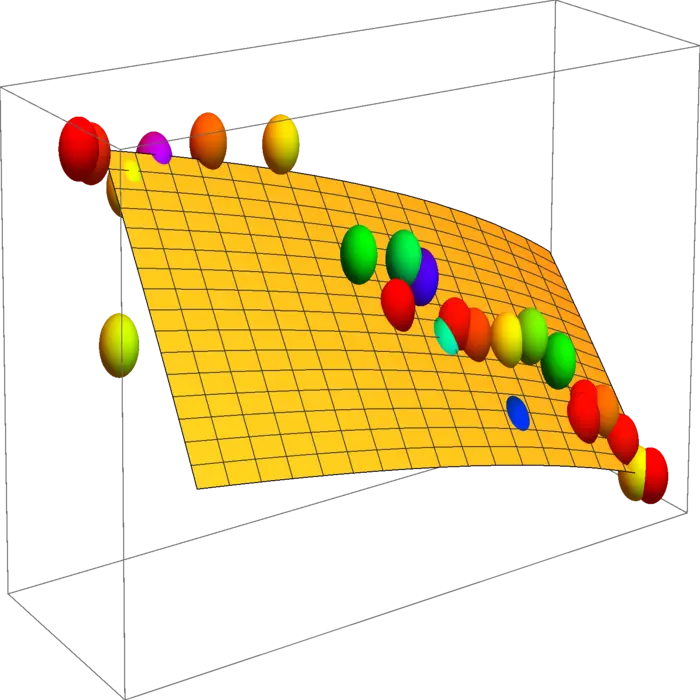
20.3.2 Visualisation des limites de production
Supposons que le travail et l'investissement en capital soient liés par la contrainte supplémentaire . (Cette fonction n'est pas liée à la fonction car nous sommes dans un problème de Lagrange.) Où la production est-elle maximale sous cette contrainte ? Tracez les deux fonctions et .
- Cet exemple est tiré de Rufus Bowen, Lecture Notes in Math, 470, 1978↩︎