Índice
- 16.1 INTRODUCCIÓN
- 16.2 LECCIÓN
- 16.3 EJEMPLOS
- 16.4 ILUSTRACIONES
- 16.4.1 Potencia a partir del potencial: una conexión con la regla de la cadena
- 16.4.2 Caos mediante derivadas: exponentes de Lyapunov y entropía en mapas iterados
- 16.4.3 Ecuaciones de Hamilton y conservación de la energía
- 16.4.4 La regla de la cadena desbloquea las inversas
- 16.4.5 Derivación implícita: encontrar la pendiente misteriosa
- 16.4.6 Soluciones garantizadas: el teorema de la función implícita
16.1 INTRODUCCIÓN
16.1.1 Construcción de funciones complejas a partir de funciones básicas
En cálculo, podemos construir funciones más generales a partir de funciones básicas. Una posibilidad es sumar funciones como . Otra posibilidad es multiplicar funciones como . Una tercera posibilidad es componer funciones como . La composición de funciones no es conmutativa: . De hecho, tenemos que es completamente diferente de .
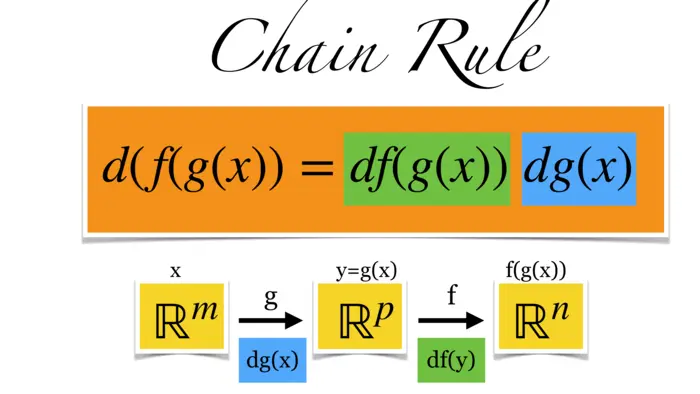
16.1.2 La regla de la cadena: de una variable a dimensiones superiores
¿Cómo podemos expresar la tasa de cambio de una función compuesta en términos de las funciones básicas que la componen? Para la suma de dos funciones, tenemos la regla de la suma (f+g)^{\prime}(x)=f^{\prime}(x)+g^{\prime}(x), para la multiplicación tenemos la regla del producto (f g)^{\prime}(x)=f^{\prime}(x) g(x)+f(x) g(x). Normalmente escribimos (f+g)^{\prime}=f^{\prime}+g^{\prime} o (f g)^{\prime}=f^{\prime} g+f g^{\prime} y no siempre escribimos el argumento. Como sabes del cálculo de una variable, la derivada de la función compuesta se da mediante la regla de la cadena. Esta es (f \circ g)^{\prime}=f^{\prime}(g) g^{\prime}. Escrito con más detalle con el argumento, podemos escribir \frac{d}{d x} f(g(x))=\frac{d}{d x} f^{\prime}(g(x)) g^{\prime}(x). Generalizamos esto aquí a dimensiones superiores. En lugar de simplemente escribimos . Esta es la matriz jacobiana que conocemos. Ahora, la misma regla se cumple como antes y esto se llama la regla de la cadena en dimensiones superiores. En el lado derecho, tenemos el producto matricial de dos matrices.
16.1.3 Dimensiones y la regla de la cadena
Veamos por qué esto tiene sentido en términos de dimensiones: y , entonces y y que es el mismo tipo de matriz que porque mapea de modo que también . El nombre regla de la cadena proviene de que trata con funciones que están encadenadas.
16.2 LECCIÓN
16.2.1 La regla de la cadena multivariable
Dada una función diferenciable , su derivada en es la matriz jacobiana . Si es otra función con , podemos combinarlas y formar . Las matrices y se combinan en el producto matricial en un punto. Esta matriz está en . La regla de la cadena multivariable es:
Teorema 1. .
16.2.2 Funciones escalares y el gradiente
Para , el caso de cálculo de una variable, tenemos d f(x)=f^{\prime}(x) y (f \circ r)^{\prime}(x)=f^{\prime}(r(x)) r^{\prime}(x). En general, ahora es una matriz en lugar de un número. Al verificar una sola entrada de la matriz, nos reducimos al caso . En ese caso, es una función escalar. Mientras que es un vector fila, definimos el vector columna Si es una curva, escribimos r^{\prime}(t)= [x_{1}^{\prime}(t), \cdots, x_{p}^{\prime}(t)]^{T} en lugar de . El símbolo también se llama "nabla".1 El caso especial es:
Teorema 2. \frac{d}{d t} f(r(t))=\nabla f(r(t)) \cdot r^{\prime}(t).
Demostración. es el límite de \begin{aligned} & \big[f\big(x_{1}(t+h), x_{2}(t+h), \ldots, x_{p}(t+h)\big)-f\big(x_{1}(t), x_{2}(t), \ldots, x_{p}(t)\big)\big] / h \\ = & \big[f\big(x_{1}(t+h), x_{2}(t+h), \ldots, x_{p}(t+h)\big)-f\big(x_{1}(t), x_{2}(t+h), \ldots, x_{p}(t+h)\big)\big] / h \\ + & \big[f\big(x_{1}(t), x_{2}(t+h), \ldots, x_{p}(t+h)\big)-f\big(x_{1}(t), x_{2}(t), \ldots, x_{p}(t+h)\big)\big] / h+\cdots \\ + & \big[f\big(x_{1}(t), x_{2}(t), \ldots, x_{p}(t+h)\big)-f\big(x_{1}(t), x_{2}(t), \ldots, x_{p}(t)\big)\big] / h \end{aligned} que es (regla de la cadena en 1D) en el límite la suma f_{x_{1}}(x) x_{1}^{\prime}(t)+\cdots+f_{x_{p}}(x) x_{p}^{\prime}(t).
Demostración del caso general: Sea . La entrada de la matriz jacobiana es . El caso de la entrada se reduce con y al caso en que es una curva y es una función escalar. Este es el caso que ya hemos demostrado. ◻
16.3 EJEMPLOS
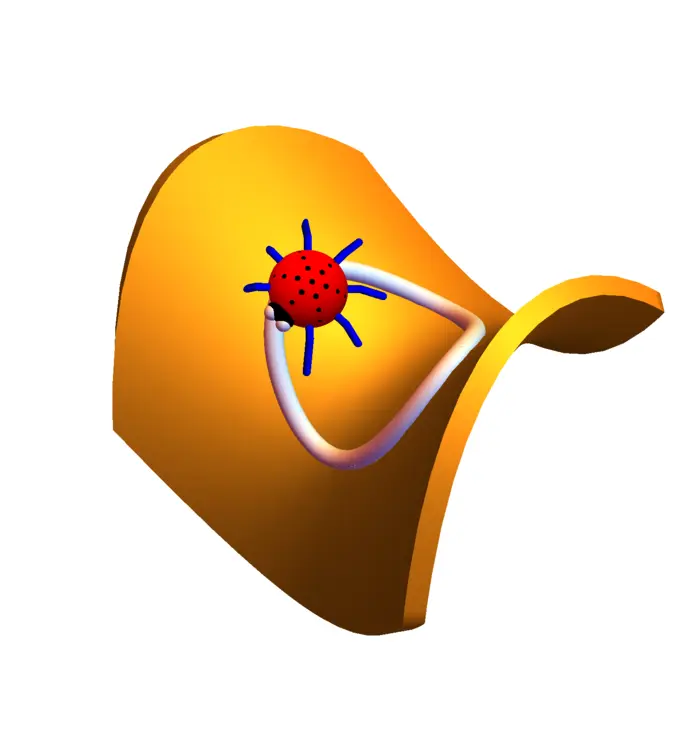
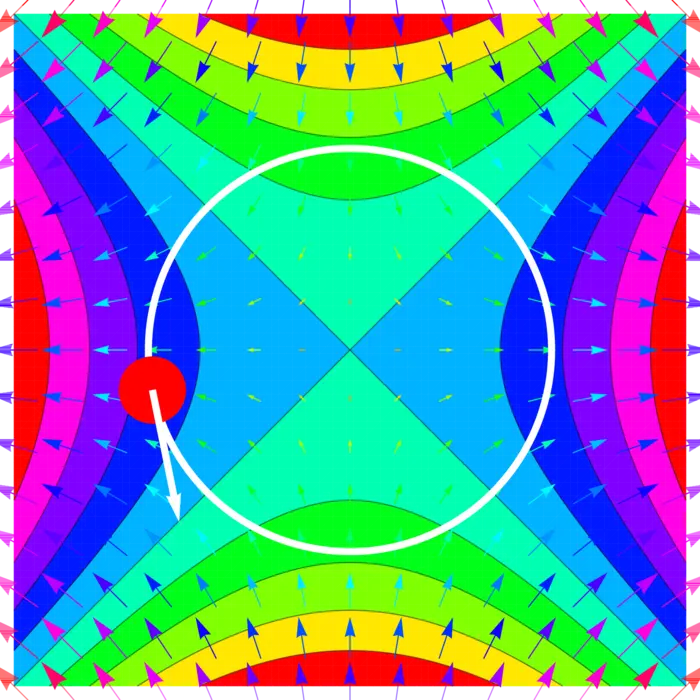
Ejemplo 1. Supongamos que una mariquita camina sobre un círculo y es la temperatura en la posición , entonces es la tasa de cambio de la temperatura. Podemos escribir Ahora, . El gradiente de y la velocidad son \nabla f(x, y)=\left[\begin{array}{r}2 x \\ -2 y\end{array}\right], \quad r^{\prime}(t)=\left[\begin{array}{r}-\sin (t) \\ \cos (t)\end{array}\right]. Ahora \begin{aligned} \nabla f(r(t)) \cdot r^{\prime}(t)&=\left[\begin{array}{r} 2 \cos (t) \\ -2 \sin (t) \end{array}\right] \cdot\left[\begin{array}{r} -\sin (t) \\ \cos (t) \end{array}\right]\\ &=-4 \cos (t) \sin (t)\\ &=-2 \sin (2 t). \end{aligned}
16.4 ILUSTRACIONES
16.4.1 Potencia a partir del potencial: una conexión con la regla de la cadena
El caso es extremadamente importante. La regla de la cadena \nabla f(r(t)) \cdot r^{\prime}(t) dice que la tasa de cambio de la energía potencial en la posición es el producto punto de la fuerza en el punto y la velocidad con la que nos movemos. El lado derecho es potencia fuerza por velocidad. Usaremos esto más adelante en el teorema fundamental de las integrales de línea.
16.4.2 Caos mediante derivadas: exponentes de Lyapunov y entropía en mapas iterados
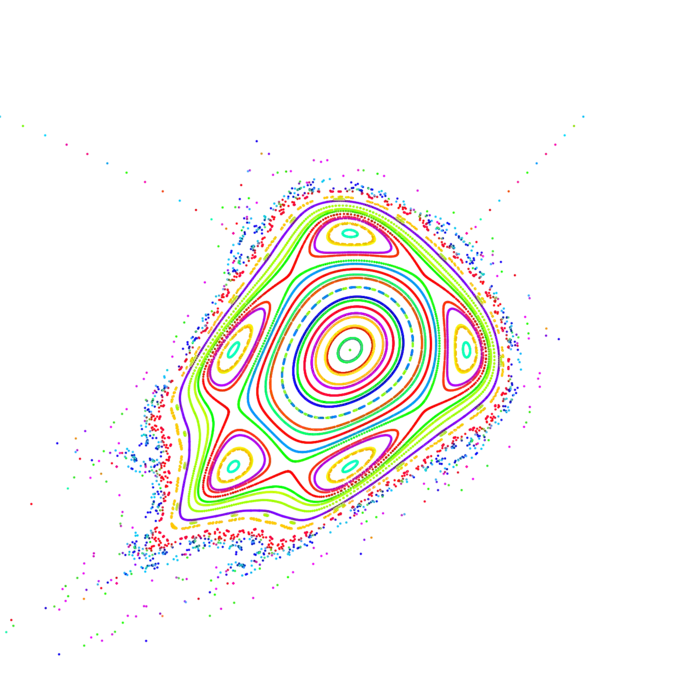
Si , entonces es nuevamente un mapa de a . También podemos iterar un mapa como La derivada es por la regla de la cadena el producto de matrices jacobianas. El número se llama el exponente de Lyapunov del mapa en el punto . Mide la cantidad de caos, la "dependencia sensible de las condiciones iniciales" de . Estos números son difíciles de estimar matemáticamente. Ya para ejemplos simples como el mapa de Chirikov se puede medir entropía positiva . Una conjetura de Sinai dice que la entropía del mapa es positiva para grande. Mediciones muestran que esta entropía satisface . La conjetura sigue abierta.2
16.4.3 Ecuaciones de Hamilton y conservación de la energía
Si es una función llamada el hamiltoniano y x^{\prime}(t)=H_{y}(x, y), y^{\prime}(t)= , entonces . Esto se puede interpretar como conservación de la energía. Vemos que una ecuación diferencial hamiltoniana siempre conserva la energía. Para el péndulo, , tenemos x^{\prime}=y, y^{\prime}=-\sin (x) o x^{\prime \prime}=-\sin (x).

16.4.4 La regla de la cadena desbloquea las inversas
La regla de la cadena es útil para obtener derivadas de funciones inversas. Como \begin{aligned} 1=\frac{d}{d x} x&=\frac{d}{d x} \sin (\arcsin (x))\\ &=\cos (\arcsin (x)) \arcsin ^{\prime}(x) \end{aligned} lo que luego da \begin{aligned} \arcsin ^{\prime}(x)&=1 / \sqrt{1-\sin ^{2}(\arcsin (x))}\\ &=1 / \sqrt{1-x^{2}}. \end{aligned}
16.4.5 Derivación implícita: encontrar la pendiente misteriosa
Supongamos que es una curva. No podemos despejar . Sin embargo, podemos suponer . La derivación usando la regla de la cadena da f_{x}(x, y(x))+f_{y}(x, y(x)) y^{\prime}(x)=0. Por lo tanto y^{\prime}(x)=-\frac{f_{x}(x, y(x))}{f_{y}(x, y(x))} En el ejemplo anterior, el punto está en la curva. Ahora y . Entonces, g^{\prime}(1)=-7 / 6. Esto se llama derivación implícita. Podríamos calcular con ella la derivada de una función que no se conocía.
16.4.6 Soluciones garantizadas: el teorema de la función implícita
El teorema de la función implícita asegura que existe una función implícita diferenciable cerca de una raíz de una función diferenciable .
Teorema 3. Si , existe y una función con .
Demostración. Sea tan pequeño que para un fijo, la función tiene la propiedad y y h^{\prime}(y) \neq 0 en . El teorema del valor intermedio para asegura ahora una raíz única de cerca de . La fórmula de la regla de la cadena anterior asegura entonces que para , el cociente diferencial escrito para tiene un límite . ◻
P.D. Podemos obtener la raíz de aplicando pasos de Newton T(y)=y-h(y) / h^{\prime}(y). Taylor (que se verá en la próxima clase) muestra que el error se eleva al cuadrado en cada paso. El paso de Newton funciona también en dimensiones arbitrarias. Se puede demostrar el teorema de la función implícita simplemente estableciendo que Id es una contracción y luego usar el teorema del punto fijo de Banach para obtener un punto fijo de que es una raíz de .

Las unidades 16 y 17 se enseñan juntas el miércoles. La tarea está toda en la unidad 17.
- La etimología dice que el símbolo está inspirado en un arpa egipcia o fenicia.↩︎
- Para generar órbitas, consulte http://www.math.harvard.edu/k̃nill/technology/chirikov/.↩︎